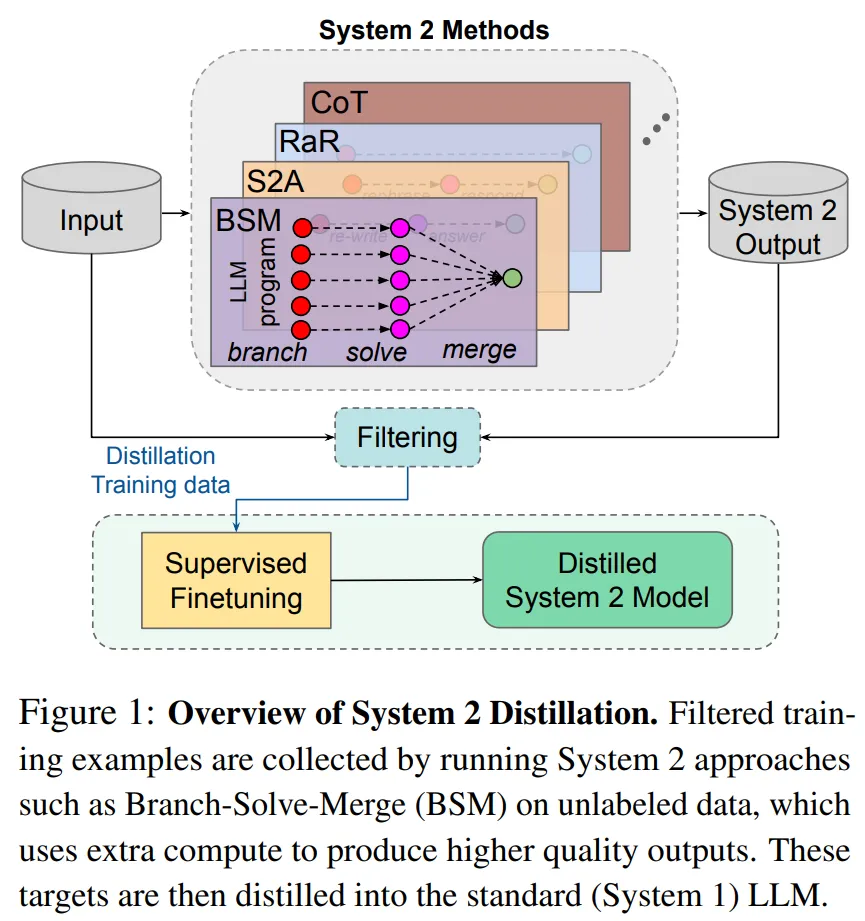
Meta开发System 2蒸馏技术,Llama 2对话模型任务准确率接近100%
Meta开发System 2蒸馏技术,Llama 2对话模型任务准确率接近100%研究者表示,如果 Sytem 2 蒸馏可以成为未来持续学习 AI 系统的重要特征,则可以进一步提升 System 2 表现不那么好的推理任务的性能。
来自主题: AI技术研报
10973 点击 2024-07-14 13:36
 搜索
搜索
研究者表示,如果 Sytem 2 蒸馏可以成为未来持续学习 AI 系统的重要特征,则可以进一步提升 System 2 表现不那么好的推理任务的性能。

全球首个芯片设计开源大模型SemiKong正式发布,基于Llama 3微调而来,性能超越通用大模型。未来5年,SemiKong或将重塑价值5000亿美元的半导体行业。

来自佐治亚理工学院和英伟达的两名华人学者带队提出了名为RankRAG的微调框架,简化了原本需要多个模型的复杂的RAG流水线,用微调的方法交给同一个LLM完成,结果同时实现了模型在RAG任务上的性能提升。

导读:时隔4个月上新的Gemma 2模型在LMSYS Chatbot Arena的排行上,以27B的参数击败了许多更大规模的模型,甚至超过了70B的Llama-3-Instruct,成为开源模型的性能第一!

可在单张A100/H100 GPU或TPU主机上高效运行全精度推理。
如何无痛玩转Llama 3,这个手把手教程一看就会!80亿参数推理单卡半分钟速成,微调700亿参数仅用4卡近半小时训完,还有100元代金券免费薅。
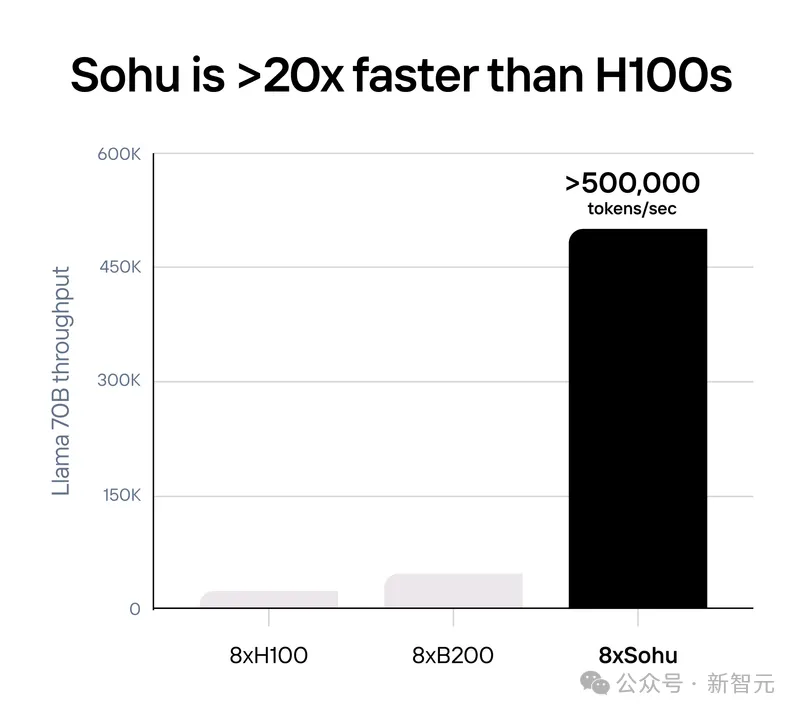
史上最快Transformer芯片诞生了!用 Etched chip 跑Llama 70B,推理性能已超B200十倍,超H100二十倍!刚刚,几位00后小哥从哈佛辍学后成立的公司Etached,宣布再融资1.2亿美元。

是时候把数据Scale Down了!Llama 3揭示了这个可怕的事实:数据量从2T增加到15T,就能大力出奇迹,所以要想要有GPT-3到GPT-4的提升,下一代模型至少还要150T的数据。好在,最近有团队从CommonCrawl里洗出了240T数据——现在数据已经不缺了,但你有卡吗?
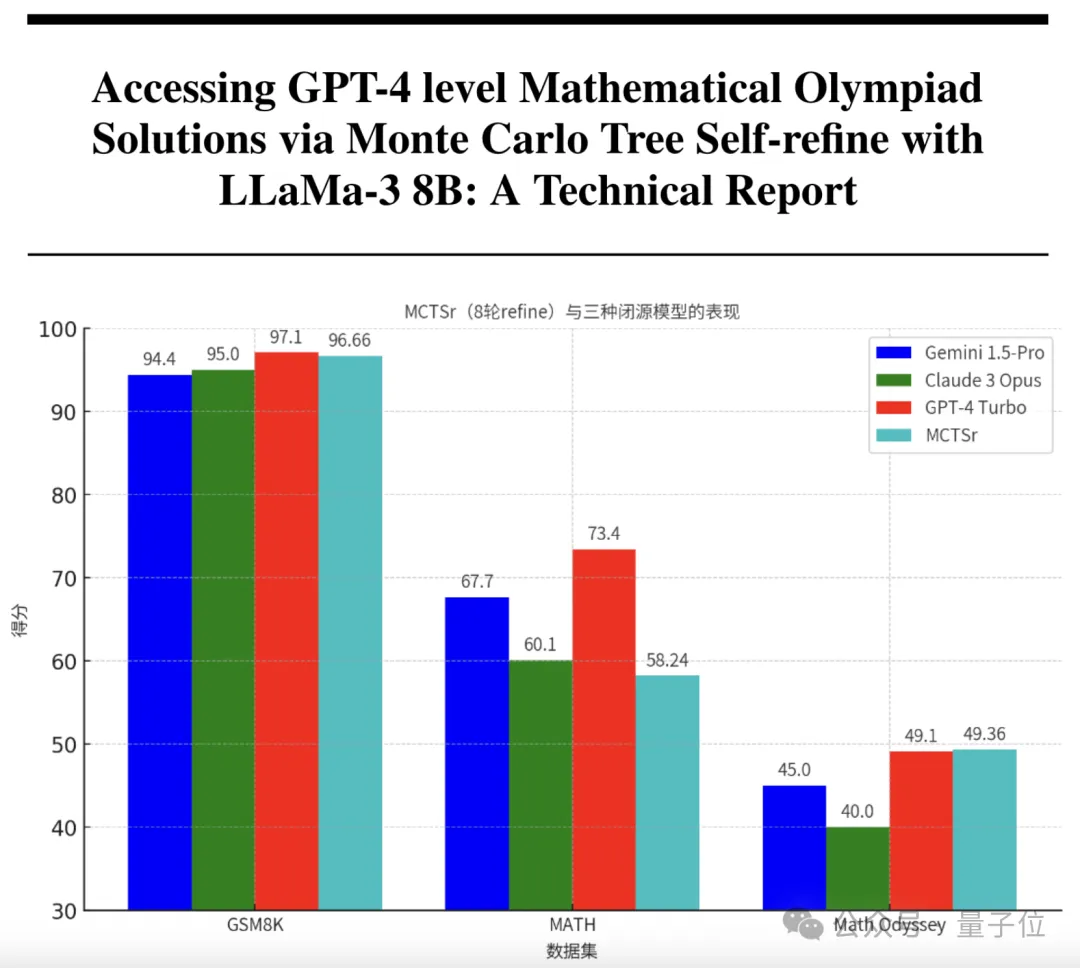
只要1/200的参数,就能让大模型拥有和GPT-4一样的数学能力? 来自复旦和上海AI实验室的研究团队,刚刚研发出了具有超强数学能力的模型。 它以Llama 3为基础,参数量只有8B,却在奥赛级别的题目上取得了比肩GPT-4的准确率。

近些年,语言建模领域进展非凡。Llama 或 ChatGPT 等许多大型语言模型(LLM)有能力解决多种不同的任务,它们也正在成为越来越常用的工具。